I am not an expert in AI, but I have seen a lot of waves software-based productivity innovations in my lifetime, and have developed some intuition as to how fast or slow they can penetrate corporate America.
I think the impact of AI over the next 5 years, particularly on productivity, has been exaggerated. Which should be no surprise as the impact of PC's and later the Internet also undershot their productivity expectations for the first 5 years.
On the positive side, current AI models have an immense ability to improve decision-making. Clearly the ability to do faster and sometimes better research supports all kinds of decision-making. In my old world of hospitality, I can see immediate application to things like better dynamic pricing decisions and (in peaky/seasonal businesses) better staffing predictions. Investment decisions, trading, inventory management, sales force targeting, and many other such data-intensive decisions likely can be improved with current AI models. But these are mostly cases where the financial impact is NOT based on workforce reduction and labor productivity.
From a pure person-replacement perspective, the best use case I have seen is in startups. AI can be a godsend for entrepreneurs and small startups that are trying to perform business activities that large companies have whole departments for, but for them might be a quarter person -- eg website design and maintenance. Given that these startups have no legacy systems or organizations, AI could conceivably become the backbone of a large company some day as they grow.
The problem with AI is its current untrustworthiness and error rate. If a startup has some crazy glitch on an AI-generated web site, it probably is not that damaging but the stakes are much higher for established companies. The problem in my mind boils down to the AI's lack of skepticism.
Everyone has heard of Descartes "I think therefore I am," but his actual logic was a bit different. It can best be summarized as "I doubt, therefore I think, therefore I am." The core of thinking for Descartes was doubt, or as I call it, skepticism. By Descartes' definition, can AI be actually thinking without skepticism?
This isn't a problem limited to AI -- much of the human race seems to have lost the ability to be skeptical. It seems everyone is really good at a knee-jerk skepticism of anything originating across the political aisle, but the capacity for skepticism for one's own work or for inputs that reinforce one's core beliefs is limited.
For several years in the 1990's I managed consulting teams at McKinsey. When analysts and associates came back to me with estimates and models, my role was frequently to demand that they have some skepticism about their own results -- does this final number make any sense at all? I remember one associate (who eventually rose much higher in the Firm than I did) bringing me a market model and proudly showing an addressable market in the trillions of dollars (this was before the SpaceX IPO when they -- with a straight face -- claimed an addressable market of $28.5 trillion). I asked him if this number made any sense at all to him. He said that's what came out of the spreadsheet. I said that when you saw that number, your first reaction should have been to think "wow, there is something wrong in my spreadsheet."
Without any built-in capacity to be skeptical or to reality-check its own results, AI has already been leading some companies over the cliff
Almost every day in the legal world we see firms getting sanctioned by judges for including non-existent cases and references in their briefs, obviously a result of some AI hallucination. This has become so common that I actually considered a business a year ago that would hire itself out to review legal briefs for firms and scrub out the AI influence. When I talked earlier of there being higher stakes in existing businesses, this is a good example -- cases are being thrown out and attorneys are being sanctioned and disbarred over AI failures.
I know some young people in the same sorts of consulting jobs I was in 30 years ago and they report that as a case manager a lot of their time is spent scrubbing out AI crap from the analysis submitted by their associates. I have a standing prediction that a public embarrassment is coming soon to one of the major consulting companies as a client cries foul over paying millions in consulting fees for ChatGPT output.
The #1 cited use case for AI to reduce manpower is in writing code. And this makes some sense to me, programming after all is just writing with its own language and grammar and punctuation. But I still am skeptical companies in high stakes situations are going to let AI write mission-critical code. There have already been a few public failures (I believe AI agents created an AWS outage a while back) and I will not be surprised to see more
My point is not that AI cannot do useful things -- it is that it will be hard (at least in the current state of things) for AI to really get rid of a lot of workers either because the stakes will be too high to chance it's substitution or because almost as many workers will have to be hired to check the results.
But that [software] is the exception. Across most of the economy, and especially in capital-intensive, heavily regulated sectors, deep process re-engineering and data governance requirements could delay structural productivity gains well beyond what the market currently projects. The list of slow-moving sectors is long, spanning health care, banking and insurance, energy and utilities, defense and aerospace, pharma and life sciences, manufacturing, transportation and logistics, construction and real estate, education, legal and the public sector.
For heaven's sakes, much of the government and a lot of the financial sector (including as many as 95% of the ATM's) run on COBOL. This is not just switching costs, it is a deep understanding of the cost of failure that drives reliance on a well-understood, reliable language platform.
AI will still be adopted in these businesses, but as an add-on decision-making aid overlayed over the top of existing systems. Which leads me to the question of what will happen to SAAS companies like Salesforce or Oracle. The stock market has hammered these companies on the theory that corporations are going to adopt AI to replace their functionality. This seems ridiculous to me. Salesforce and Oracle applications are deeply embedded in corporation workflows and they are largely trusted by their customers. These SAAS apps already have their fingers in all the corporate data after years of integration efforts. If corporations are going to adopt AI for better decision-making, are they going to hire some 21-year-old startup guys to do AI (several of whom have pitched me) or are they going to go to Salesforce and Oracle and look at their AI offerings? Two years ago I saw the Salesforce CEO speaking at HBS, and his entire pitch was on AI and what Salesforce is doing to integrate AI into its offerings.
One final thought -- these corporations are NOT going to need the most token- and memory-hungry bleeding-edge AI models to do most of what they want to do. They want something less error-prone, sure, but the mid-tier product is going to be good enough (think of it this way, few computers bought by large corporations have super-high-end graphics cards or processors). And the mid-tier good enough AI already uses a lot fewer processing resources than the bleeding edge ones, and they will continue to get more compact and efficient over time. The point being is that the great data center scramble is likely something of a bubble in the same way companies like Enron were left wondering what happened to that big potential broadband market.
Postscript: The specific case of AI for resume screening is an interesting and evolving example. There is clearly a huge time saving (and perhaps quality improvement) if one can reliably plop 200 incoming resumes and have AI sort it down to the best 10 or so. The error problem is not a huge issue (at least for the company) as missing one good candidate out of the 200 is not fatal (there are still 10 others) and putting one bad candidate in the 10 is also not fatal (they will be human screened as a next step anyway). But then job seekers learned about AI screening and use AI now to optimize their resumes, LinkedIn pages, and cover letters to pass corporate AI screens. Soon hiring will be worker AIs talking to corporate AIs. My prediction is that the ultimate productivity savings will be low, as companies are going to have to get human to human contact to screen potential employees.
I have been recuperating from some health issues and have not been writing much, but I really don't want to miss out on putting my oar in the water prior to the SpaceX IPO. As background, I love to watch what SpaceX is doing in launch and believe they have made a huge contribution to the world in doing so. As a former operator of hundreds of wilderness campgrounds, Starlink was the greatest single new technology for our business in 20 years. But you don't automatically get your way with stock valuations just because what you do is cool and useful -- there has to be some prospect of making back the investment.
Anyone who has been following Tesla for years has to know what is coming at SpaceX. In the movie Gettysburg, the great Sam Elliot speaks these lines as General Buford, the union Cavalry commander who was able to slow the southerners just enough on day 1 to let the Union grab the high ground. But ahead of this success, he fears that he and the union will fail and the South would slaughter Union troops trying to take the hills too late, as at Fredericksburg (and as happened to Pickett a couple days later).
Devin, I've led a soldier's life, and I've never seen anything as brutally clear as this. It's as if I can actually see the blue troops in one long, bloody moment, goin' up the long slope to the stony top. As if it were already done... already a memory. An odd... set... stony quality to it. As if tomorrow has already happened and there's nothin' you can do about it. The way you sometimes feel before an ill-considered attack, knowin' it'll fail, but you cannot stop it. You must even take part, and help it fail.
Having been a (peripheral) part of the online community skeptical of Tesla stock valuation, I feel I can see the future of SpaceX stock over time as if it has already happened.
There are at least two distinct patterns one sees over time in the stock of Musk-led Tesla that I fully expect to see duplicated at SpaceX. So it is worth reviewing those.
1. Absurd Valuation Based on Musk Shouting "Squirrel"
Tesla has a Trailing 12 Month PE ratio of 387(!) and a forward PE of 216. These ratios are almost unprecedented for a company not in the middle of a restructuring, and indicate simply enormous growth expectations. This is not some weird temporary data spike... Tesla has maintained a PE over 150 for years and years. Just to give it context, let's compare it to Nvidia which is perhaps the world's most famous growth company right now. Nvidia's revenues have really gone vertical over the last quarters:
For that it has been rewarded with a PE of 34 / 25 (Trailing / Forward). So Tesla must REALLY be growing to justify a PE of nearly 400, right? Well, not really. In fact, Tesla's revenue has been essentially flat for 14 quarters:
So how does Tesla maintain such a crazy-high valuation? Honestly, I don't know. But from watching it and Musk for years I would argue that the most important factor has been Musk's ability to keep shifting the endgame. The response to valuation concerns is always "yeah, but you are only looking at the current business, [fill in the blank] which is coming soon[-ish] will be worth a trillion dollars." The fill-in-the-blank over the years has included solar roofs, full self-driving, semi-trailers, battery swap, robo-taxis, neural implants, humanoid robots, and AI.
Tesla Translated to SpaceX: The proposed SpaceX valuation of $1.75 trillion is, if anything, even crazier than Tesla's. It is impossible to apply a PE, since SpaceX loses money and can be expected to do so for years, even decades. But with about $18.7 billion in revenue last year, the SpaceX valuation is nearly 100x revenue (Tesla trades at a lofty 15x revenue). Nobody, ever, has made money investing in a 20-year-old company with low margins at 100x revenue (barring the occasional sucker who will later pay 120x).
The tell for me is the emphasis and investment in AI at SpaceX. Strategically, this is a terrible idea as their core business is already very capital intensive and they really don't need a diversion into something else. They are competing in AI with a number of companies that are far ahead of them and I don't see an obvious way to catch up (very similar to Tesla and self-driving). Musk says they are ahead but Musk said Tesla was ahead on self-driving and robotaxis until it has become obvious that they are not even close. There is a potential AI-related launch and hardware opportunity, maybe, someday, to put AI processing in space, but there is no reason that should be dependent on SpaceX's independent investments in AI. The one thing AI gives SpaceX, of course, is a squirrel to help fill in the value hole between "losing money on $18 billion of revenue" and $1.75 trillion. Investors in SpaceX can expect a constant stream of squirrels over the coming years.
2. Propping Up Older Musk Investments with Newer Ones
Over the years of following Musk, the one action of his that aggravated me more than anything else was the transparent bailout of his friends' and family's investment in SolarCity using Tesla stock. Like most other rooftop solar businesses, in 2016 SolarCity was close to bankruptcy. Rather than allowing that to happen, losing money and prestige for Musk, Musk used his extraordinary control of the Tesla board to have Tesla buy out SolarCity for far more than any sensible market value. In doing so, Musk trumpeted another classic Tesla squirrel, presenting the Solar Roof, basically modular rooftop solar tiles that looked like wood or slate that would snap together into an attractive rooftop installation. It was later found that most of the early demo was likely fake, as the tiles were not even close to release-ready and while Musk was predicting 12,000 installations per year and growing, perhaps only 3000 in total were ever completed over 10 years. The Solar City results continued to fall at Tesla and were rapidly buried in the energy sector, making it almost impossible to figure out how much value Tesla got from SolarCity, given that the vast majority of energy sector revenues are unrelated to rooftop solar and are instead large battery storage projects.
Since that time Musk has used his AI lab xAI to buy Twitter/X. And then just this year had SpaceX buy xAI for $250 billion. Does it make sense that an orbital launch company own a social media platform? Absolutely not, but it bailed Musk out of an investment in X that was going to be very hard to ever recover any other way.
Tesla Translated to SpaceX:
Last year Tesla booked $890 million in revenue from SpaceX (cars, battery storage, some AI). This is less than 1% of Tesla's revenues though I expect it to be, since it was not arms length, more profitable than average. But the real threat to SpaceX will be, as Tesla's stock valuation eventually starts to return to Earth, that Musk will use his unique control of both companies to have SpaceX buy Tesla. People are already discussing it. These are two companies that absolutely have no reason to be under one roof EXCEPT that it would help maintain Musk's net worth. Yes, I am sure he will generate a logic that the Musk fan-boys will love -- AI consolidation or some such. And I guess it would be accretive, in an ugly way, with a 100x revenue company buying out a 15x. Just remember that these two companies, which if the IPO price holds for SpaceX, have a combined market cap of $3 trillion and a combined 2025 net income of -$1 billion. Even if your excel spreadsheet has enough columns to add years marching towards the heat death of the universe, I am not sure that investment ever pays off.
Parting Thoughts
None of this necessarily means that the SpaceX IPO will fail or that SpaceX stock won't rise post-IPO. I spent too many years getting burned off and on shorting Tesla to ignore the fact that any Musk enterprise commands a premium among a subset of investors -- he is like Warren Buffet in that his name association with a deal has overwhelming value (the only difference from Buffet being that Buffet's investments actually produce profits). Be aware if you invest that you are likely soon to own Tesla as well, because I do not think Musk can resist the temptation to use high-multiple SpaceX stock as wampum to buy out his other investments.
There is a sort of clock in Musk investments, going back to SolarCity. There is a lot of arm-waving and squirrels to maintain a valuation, but as business performance inevitably does not live up to the valuation hype, its time to have the next investment that is at the peak of its hype with a huge multiple buy out the old one. I really thought Tesla might finally hit that point when the valuation collapses to that of a low-growth car company once the robotaxi initiative proved a loser, but here comes SpaceX just in time.
I do not give out investment advice but if I were short Tesla right now I would run for my life. The SpaceX IPO will essentially be a big Tesla bailout.
I am not going to get into any ethical or legal arguments about the decapitation raids on Iran. I don't have the time or the heart to do it right now. I couldn't be more thrilled to see the leadership of Iran eliminated but the legal basis for all this is slim. Of course every President this century has done something similar, sometimes with far less provocation, so the precedent train already left the station long ago. I will, however, offer one practical issue.
The US is really good at getting rid of leaders like this, and if anything is getting better. I won't go further back than my lifetime, but the Diem coup (and execution) in South Vietnam, the lukewarm (at best) support for the Shah of Iran that contributed to his ouster, Saddam Hussein in Iraq, the Afghanistan invasion, Gaddafi in Libya, Maduro in Venezuela, Noriega in Panama -- the list goes on. But in many or most of these cases, what followed the US-led decapitation was as bad or worse than what came before. Vietnam - equally bad or worse. Iran - worse. Iraq - better but took a really long commitment. Afghanistan - at least as bad or worse. Venezuela - unknown but no immediate revolution as hoped. Libya - much worse. Panama - probably better.
We have no historically successful roadmap to go by, and in a sense this may be a situation like Hayek's critique of government planning -- that a perfect roadmap cannot exist because we don't understand the mass of individuals we are "liberating", or even how they define "liberated', or even if they really want to be "liberated." As all of us humans do, we project our own preferences and outlooks and assumptions on people where they may well not fit at all.
Even beyond the job of seeing Iran no longer acting as a leading agent of chaos, I would greatly love to see their people liberated. Women in Iran who were just emerging into the 20th Century under the Shah's leadership have a chance to emerge from gender apartheid again, and I am 100% hoping to see this. (I wrote a while back about the utter lunacy of US women on the Left consistently siding with hardcore Islam and ignoring the plight of women in these countries).
Unfortunately for my optimism, I said the exact same thing, almost word for word, when we invaded Iraq. Iraq has since struggled to fulfill this promise, though to be fair a lot of the blame for that rests not on US failures or the Iraqis but on the ongoing efforts by Iran to subvert the country and keep it roiled in chaos. But getting there took a HUGE US commitment of money and lives, way more than a pushbutton decapitation of the leadership.
A parting thought -- there is clearly an Iranian opposition. We have seen them bravely marching in the streets (far braver than our anti-fascists here as they faced actual imprisonment and death for such protests against real fascists). This is an honest question -- around whom does the Iranian opposition rally and organize? As in many such authoritarian societies, only the authorities have organization. So even decapitated, the military and former government theoretically have a huge head start in pulling things together under their control in the aftermath than an unorganized populace. This is the same problem faced by many post-colonial governments. It's not that their populace wanted a military dictatorship when the colonizer left or was thrown out, but in many cases the only organized and educated group in the country was the military which stepped into the vacuum. I am not an expert on this but I have always assumed India escaped this fate because it had a relatively large, educated group of indigenous people trained in government and not in the military.
Postscript: I continue to find it sort of hilarious that media that go out of their way not to deadname a transexual teen insist on describing Iran as part of the Arab world and their citizens as Arabs. I can tell you with great confidence and many experiences that there is no way to piss off an Iranian faster than to call them an Arab.
I still think my first reaction to the Left's pushback on DOGE's probe of the spending of USAID and later other government departments was on target:
The $$ that DOGE is looking at now are the funding source for a lot of the Democratic (and some of the Republican) base. My guess is that even much of the international spending is flowing back to US-based influence groups.
Which led to this meme (it's an old standby but under @boriquagato influence I am dipping my toe into meme creation:
As an aside, I am fully supportive of addressing real privacy abuses found in the DOGE process, though having these concerns come from the party and the media complex that spent the last four years trying to leak Donald Trump's and other rich people's tax returns and whose first response to these privacy concerns was to dox members of Musk's analytical crew makes me skeptical this is the real concern. For government workers, "privacy" means keeping secret bad or stupid decisions. Remember this one (which was again about covering up spending)?
Some of the questionable redactions, by contrast, are charming efforts at bureaucratic butt-covering. Lisa Page, for example, was discussing with Peter Strzok the challenge of having an intimate meeting in Andrew McCabe’s conference room, given the size of his grand new conference table. “No way to change the room,” Page texts in the version provided by Justice. “The table alone was [REDACTED]. (You can’t repeat that!)” Hmmm, what classified, top-secret, national-security information could possibly have been redacted? The blacked out bit, it seems, was a simple “70k.” The DoJ—and can you blame them, really?—didn’t want Congress to know they were in the habit of spending $70,000 on a conference table.
Update 2-17: DOGE is seeking access to IRS systems with taxpayer data. As loath as I am to slow this effort down, I think we need to hear about some strong controls before this proceeds.
But having thought about this longer, I think this is about more than just money. It is also about class. Just listen to how the cool kids in the media talk about Musk's group of young weirdly-nicknamed geeks. This is fairly typical:
He was speaking specifically about a Trump executive order that decrees that the Department for Government Efficiency can force federal agencies into firing four people for every new hire. “Who the hell voted for Mr. Musk?” Begala raged. “Who the hell voted for—excuse the phrase—a guy who calls himself Big Balls? A 19-year-old kid going in there and trying to fire cancer researchers and scientists and teachers and agricultural specialists. It’s, it’s appalling.”
This is moderately hilarious from a) a party who still has not told us which unelected people really were making decisions behind the curtain for a senile Joe Biden; and b) an individual (Begala) who wielded immense power and influence across all departments of the Clinton Administration. The department staffs in DC are 99.99% people who are both unelected and unconfirmed by Congress. The issue is not that they are unelected, the issue is that they are "the wrong sort." I am reminded of the British aristocracy in the 19th century that would tolerate almost any sort of governmental incompetence or malfeasance as long as the people were "the right sort" -- meaning of their class.
The mention of Victorian England reminds me of another way that class is likely involved here. In the English aristocracy the oldest son inherited the title and often all the land and income (which was entailed to the title). This left little for any additional sons, so an income had to be found somewhere for them in a profession that did not require them to sully themselves with "trade" (daughters were handled a different way, through the marriage market). Reading for the law was an acceptable profession for a son with brains, and the army or navy were outlets for many. But most families needed a way for their sons without too much brains or ability and not militarily inclined to make a living. A position in the Church was often the solution.
Modern American blue-blood parents are no different -- they need a way to secure a living for their kids who won't or can't land a job in the modern elite career choices (law, consulting, investment banking, or a sexy startup). Unlike in Victorian times, the military or the Church are no longer preferred elite options? So what to do with your 22-year-old gender studies major? The parents need her to get an income and they need her to do it in a context that they can proudly report to their friends -- Paul Begala does not want to tell his friends that his son's job is maintaining distributor pricing lists ** (anyone who does not believe the latter criteria should have been at my Princeton or Harvard Business School 25th reunions).
The solution? Get them a job at a non-profit, the modern American version of going to the Church. As Arnold Kling noted once, non-profits tend to have much higher status than do for-profits. And without competition they don't have to carry the same performance standards as for-profits. And they are incredibly susceptible to trading a position for your kid in exchange for a nice donation.
The employment rosters of non-profits and NGO's are stuffed with the children of privilege. So much so that there are many non-profits that seem to do nothing EXCEPT employ and pay the travel expenses of 20-something kids from rich and/or influential families. I have been writing about the non-profit scam for years. As I wrote then:
From my direct experience, I would go further. There is a tranche (I don't know how large) of non-profits that are close to outright scams, providing most of their benefits to their managers and employees rather to anyone outside the organization. These benefits include 1) a salary with few performance expectations; 2) expense-paid parties and travel; 3) myriad virtue-signalling opportunities; 4) opportunities to build personal networks. This isn't just criticizing theoretical institutions -- people I know are in such jobs in these organizations.
The spending that DOGE is going after at USAID and other departments likely threatens the income of a number of under-qualified elite kids. So I will update my meme:
**Footnote: I will proudly tell the world that my son's first job out of college was indeed maintaining distributor pricing lists for Ballast Point beer. Trying to optimize profits across the matrix 100+ sku's and scores of distributors is a great real world skill building entry-level job that so many of the change-the-world-before-I-am-25 college kids currently eschew.
Postscript: If you want the blank template for the Astronaut meme updated for DOGE, I share it here.
Quite a while ago I wrote an article about climate publication bias called Summer of the Shark.
let's take a step back to 2001 and the "Summer of the Shark." The media hysteria began in early July, when a young boy was bitten by a shark on a beach in Florida. Subsequent attacks received breathless media coverage, up to and including near-nightly footage from TV helicopters of swimming sharks. Until the 9/11 attacks, sharks were the third biggest story of the year as measured by the time dedicated to it on the three major broadcast networks' news shows.
Through this coverage, Americans were left with a strong impression that something unusual was happening -- that an unprecedented number of shark attacks were occurring in that year, and the media dedicated endless coverage to speculation by various "experts" as to the cause of this sharp increase in attacks.
Except there was one problem -- there was no sharp increase in attacks. In the year 2001, five people died in 76 shark attacks. However, just a year earlier, 12 people had died in 85 attacks. The data showed that 2001 actually was a down year for shark attacks.
The point is that it is easy for people to mistake the frequency of publication about a certain phenomenon for the frequency of occurrence of the phenomenon itself. Here is a good example I saw the other day:
An emaciated polar bear was spotted in a Russian industrial city this week, just the latest account of polar bears wandering far from their hunting grounds to look for food.
Officials in the Russian city of Norilsk warned residents about the bear Tuesday. They added that it was the first spotted in the area in over 40 years.
I am willing to bet my entire bourbon collection that a) hungry polar bears occasionally invaded Siberian towns in previous decades and b) news of such polar bear activity from towns like Norilsk did NOT make the American news. But readers (even the author of the article) are left to believe there is a trend here because they remember seeing similar stories recently but don't remember seeing such stories earlier in their life.
A lawyer for Facebook argued in court Wednesday that the social media site’s users “have no expectation of privacy.”
According to Law360, Facebook attorney Orin Snyder made the comment while defending the company against a class-action lawsuit over the Cambridge Analytica scandal.
“There is no invasion of privacy at all, because there is no privacy,” Snyder said.
In an attempt to have the lawsuit thrown out, Snyder further claimed that Facebook was nothing more than a “digital town square” where users voluntarily give up their private information.
“You have to closely guard something to have a reasonable expectation of privacy,” Snyder added.
Zuckerberg really is one of the most dangerous people on the planet. He has taken well-founded criticism against his company, its failings, and its past misrepresentations and somehow morphed that into a campaign to gain totalitarian government regulation of online speech. Incredible.
I have spent pretty much zero minutes paying attention to the Kardashian women (I think I saw them more in the "People vs. OJ Simpson" than I have in all other media combined). But I have great respect for how Kim Kardashian is spending her celebrity credit. She seems to be doing real work that helps real people on an important issue, and one that does not give her the immediate virtue signalling credit as, say, making uniformed statements about the climate might.
Kim Kardashian West is staying true to her pledge to fight for prison reform.
CNN has learned that the E! star has been quietly working behind the scenes over the past three months to help commute the life sentences of 17 first-time nonviolent drug offenders.
Brittany K. Barnett, Kardashian West's personal attorney and co-founder of the Buried Alive Project, and MiAngel Cody, lead counsel of the The Decarceration Collective, told CNN that Kardashian West has been instrumental in the release of these inmates.
"Kim has been funding this project and (has been) a very important supporter of our 90 Days of Freedom campaign as part of the First Step Act, which President Trump signed into law last year," Cody said. "We've been going around the country in courtrooms and asking judges to release these inmates."
Barnett added that without Kardashian West footing the bill, this would not have been possible. "(Kim) has provided financial support to cover legal fees so that we can travel the country. Our relationships with our clients don't end when they are freed. (Kim) is truly dedicated to the issue. I work personally with her, we are really grateful."
But she's not just paying legal fees.
"When people get out of prison, they might be incarcerated hundreds of miles from their families and they might need help getting home. Really important, critical things that people might not realize -- and those are things Kim is helping with as well," Cody added.
In an authoritarian regime, those in power demand obedience but not necessarily agreement from their subjects. Even if many of their subjects might oppose the regime, the rulers are largely content as long as everyone obeys, no matter how grudgingly.
Totalitarians are different. They demand not only obedience but lockstep belief. In some sense they combine authoritarian government with a sort of secular church where attendance every Sunday is required and no heresy of any sort is permitted. Everything is political and there is no space where the regime does not watch and listen. Even the smallest private dissent from the ruling orthodoxy is not permitted. Terror from the state keeps everyone in line.
I have tried out a lot of words in my head that are less inflammatory than "totalitarian" to describe the more radical social justice elements on modern college campuses, but I can't find a word that is a better fit. The attempts to drive out dissenting voices through modern forms of social-media-fueled mob terror are both scary and extremely disheartening.
I was thinking about all this in reading an article about Camille Paglia and the students and faculty of her own university who are trying to get her thrown out. I find Paglia to be consistently fascinating, for the very reason that the way her mind works, the topics she chooses to focus on, and sometimes the conclusions she draws are very different from my own experience. The best way to describe her, I think, is that we have traditional axes of thought and she is somewhere off-axis.
Anyway, after horrifying Conservatives for many decades, Paglia has over the last few years run afoul of the totalitarian Left. One example: (emphasis added)
Camille Paglia, the controversial literary and social critic who identifies both as queer and trans, is drawing fire yet again. Students at her own institution, the University of the Arts (UArts) in Philadelphia, are calling for her to be fired. An online petition, currently with over 1,300 signatures, reads in part:
Camille Paglia should be removed from UArts faculty and replaced by a queer person of color. If, due to tenure, it is absolutely illegal to remove her, then the University must at least offer alternate sections of the classes she teaches, instead taught by professors who respect transgender students and survivors of sexual assault.
Another demand in the petition is that, if she can't be canned, the university will stop selling Paglia's books on campus and permanently disallow her from speaking on campus outside of her own classes. Although it's mostly non-faculty speakers who get deplatformed, Paglia is merely the latest target being attacked by students from her own institution. Students at Sarah Lawrence, for instance, are calling for political scientist Samuel Abrams to be fired for writing an op-ed in The New York Times calling for ideological diversity among administrators.
Paglia's critics claim that, despite her own alternative sexual identity, she is so hostile and bigoted towards trans people that her mere presence on campus constitutes an insult or threat. There's no question that she has been dismissive of some claims made by trans people and, even more so, dismissive of students who claim that being subjected to speech with which they disagree is a form of trauma.
What I got to thinking about is this: How far away are we from "her mere presence on campus" constituting a threat to being threatened by "her mere presence in the same country?" I fear it may not be very long.
Postscripts: I wanted to add a couple of postscripts to this story
I find that the "mere presence is a threat" argument being deployed by LGBT activists is extremely ironic. In the camping business I run we have always had a disproportionate number of gay couples managing individual campgrounds. Fifteen years ago I remember twice getting push back from people in the surrounding community (both times in southern, more traditionally religious areas) that the very presence of gay men around young children constituted a threat. I thought this argument was complete nonsense and basically told the protesters to pound sand. But it is ironic for me to now hear LGBT activists deploying the "mere presences is a threat" argument that has been used against them so often in history
We have clearly dumbed down what constitutes a threat when speech is equated with violence. But have we also dumbed down the concept of terror? People -- particularly university administrators but you see it all over -- constantly fold under the pressure of negative comments on twitter. This sure seems a long way from the SS showing up at your door at 4AM, but amazingly social media terror seems to be nearly as effective an instrument of control. Years ago my dad ran a major oil company and he did it with a real sense of mission, that they were doing great things to keep the world running. But he endured endless bombing threats, kidnapping threats, existential threats from Congress, screaming protests at his doorstep, etc. After being personally listed on the Unibomber's target list, I wonder what he would think about the "threat" of social media mobbing.
Most folks assume that global warming results in record high daily temperatures, but this is not necessarily the case. When your local news station blames a high temperature record on global warming, they may be wrong for two reasons.
Most of the temperature stations used by your local news channels for weather are full of urban heat island biases. This is particularly true of the airport temperature that many local news stations use as their official reading (though to be fair UHI has much more effect on evening temperatures than temperatures at the daily high).
Most global warming, at least in the US where we have some of the best records, does not occur during the day -- it occurs at night
The latter point is surprising to most folks, but as a result we are not seeing an unusual number of daily high temperature records set (many were set in the 1930s and still stand). What we are seeing instead is a large number of record high low temperature readings. This is confusing, but basically it means that the lowest temperature that is reached at nighttime is higher than it has been in the past. The chart below is a bit dated but still holds:
When I give presentations I try to use examples from local data. Here is the comparison of night time warming vs. day time warming in Amherst, MA.
I bring this all up again because Dr. Roy Spencer has done a similar analysis for the US from the relatively new AIRS database (a satellite-based data set that avoids some of the problems of land thermometer data sets like urban heat island biases and geographic coverage gaps). He shows this same finding, that over 80% of the warming we have seen recently in the US is at night.
This is a bit over-complicated because it is looking at temperatures through different heights of the atmosphere when most of you only care about the surface. But you can just look at the 0 height line to see the surface warming trend. Note that in general the data is pretty consistent with the UAH lower-troposphere temperature (satellite) and the NOAA metric (ground thermometers).
No particular point except to highlight something that is poorly understood by most folks because the media never talks about it.
It is something you see all the time -- large companies asking to be regulated, at first glance against self-interest. Those most interested in expansion of the government and the regulatory state will shout, "See! Even large evil companies know they need to be subject to government oversight."
Mark Zuckerberg, who I am increasingly convinced is the most dangerous man in America, and his testimony to Congress begging for regulation, should be seen in this context.
So in Facebook’s case, they will advocate some institutionalized changes in the way social media should work. Every change will involve compliance costs. Facebook will make sure that it can comply...and that its competitors cannot without great expense. That will give them a distinct advantage in the marketplace, make it more difficult for startups to compete, and guarantee this platform a leading place by law.
This is why Mark readily agreed to be regulated. Regulations always work to the advantage of the largest market players....
Nor should this come as some sort of shock. This is the way government regulations have always worked, from the meatpackers in the early 20th century (who crafted and enforced meatpacking legislation), to all labor legislation (it’s labor-union lawyers who exercise the dominant influence) to Bitcoin regulations (the major exchanges are always involved) to digital technology today (no way are Google and Facebook going to be excluded from writing the regulations that govern their industries).
There is a civics-text myth that imagines government workers and politicians as all-knowing, crafting rules that benefit everyone as opposed to particular players. It imagines that major market players are suffering as government forces new rules that require their operations put greed on hold and serve the public. The on-the-ground reality is otherwise. There is not a single regulation on the books that does not have an author who is unattached in some way to the regulated industry in question.
Milton Friedman called this regulatory capture. The problem is the influence of industry is there from the beginning. It’s absolutely not the case that capitalists are champions of capitalist competition, as the career and policies of Donald Trump should make clear. Lots of people are good at using markets to make money; only very special people become defenders of open competitive processes.
Right now, Facebook faces massive competition from other platforms in social media, copycats, and alternative uses of people’s time. In some ways, it’s the best possible moment to call on government to institutionalize Facebook as a form of public utility. That might actually be the end game that Zuckerberg has in mind. Then the politicians can update their timeline status: today we passed regulations that brought this wayward company to heel.
Zuckerberg said from the very beginning that he was dismissive of individual privacy and he has created the Facebook honeytrap to kill it. He now is setting his sights on free speech, begging the government to tear up the First Amendment. He is a one-man individual rights wrecking crew.
Remember the sloppily written "for the children" toy testing law that went into effect last year? The Consumer Product Safety Improvement Act (CPSIA) requires third-party testing of nearly every object intended for a child's use, and was passed in response to several toy recalls in 2007 for lead and other chemicals. Six of those recalls were on toys made by Mattel, or its subsidiary Fisher Price.
Small toymakers were blindsided by the expensive requirement, which made no exception for small domestic companies working with materials that posed no threat. Makers of books, jewelry, and clothes for kids were also caught in the net. Enforcement of the law was delayed by a year—that grace period ended last week—and many particular exceptions have been carved out, but despite an outcry, there has been no wholesale re-evaluation of the law. Once might think that large toy manufacturers would have made common cause with the little guys begging for mercy. After all, Mattel also stood to gain if the law was repealed, right?
Turns out, when Mattel got lemons, it decided to make lead-tainted lemonade (leadonade?). As luck would have it, Mattel already operates several of its own toy testing labs, including those in Mexico, China, Malaysia, Indonesia and California.
So while most small toymakers had no idea this law was coming down the pike until it was too late, Mattel spent $1 million lobbying for a little provision to be included in the CPSIA permitting companies to test their own toys in "firewalled" labs that have won Consumer Product Safety Commission approval.
The million bucks was well spent, as Mattel gained approval late last week to test its own toys in the sites listed above—just as the window for delayed enforcement closed.
Instead of winding up hurting, Mattel now has a cost advantage on mandatory testing, and a handy new government-sponsored barrier to entry for its competitors.
Prostitution is a person selling sexual services of their own free will. Trafficking is a form of kidnapping and slavery, when someone is forced to provide sexual services by someone with power over them.
All or even most prostitution is not trafficking, but many in the media and political sphere use these two a synonyms. I have seen it all week surround the Robert Kraft bust for seeking a private happy ending even before his team played in the Superbowl. I see this as a victory of traditionally anti-prostitution folks on the Right who have found a way to take advantage of a division on the Left, and specifically a division within feminism, to rebrand prostitution and bring some folks on the Left over to their side.
I am not an expert on feminist politics, but what I do know is the prostitution has created a divide among feminists. You remember the old abortion chant that feminists wanted the government to keep its laws off their body? That what a woman did with her body was an eminently private affair and should not be subject to government regulations? Well, feminists who followed up on this thought in a consistent manner generally supported legalization of prostitution. Bans on prostitution were seen by these folks as just another example of the male-dominated system limiting women's choices and ability to make money the way they choose.
On the other side more modern feminists see everything through the prism of male power over women. This is the "all sex is rape" group and for them prostitution has nothing to do with women's free will and everything to do with yet another channel through which men objectify and dehumanize women. From here it's only a small step to thinking that all prostitution is slavery. And thus by attempting to rebrand prostitution as trafficking, the Right found new allies on the Left in their campaign against sex work.
Those who read me a lot know I come down on the side of women being able to exercise choice, and I think the only real dehumanizing going on is the denial by modern feminists of any agency among most women.
But real abusive trafficking certainly exists. How much of prostitution fits this category is impossible to really know as a layman because the media and activists do so much to blur the line in their reporting. But I will say this: To the extent trafficking exists, it is not enabled by society somehow being soft on prostitution, in fact it is enabled by the opposite. By making prostitution illegal, we give unscrupulous people leverage to abuse those in sex work. Women being abused by men at, say, Wal-Mart have many legal outlets to air their grievances and seek change or compensation -- no one talks about trafficking in Wal-Mart greeters. But abused sex workers cannot go to the legal system for redress of abuse because they themselves are treated as criminals in the system. Contributing to this is our restrictionism on immigration. This is why many real trafficking cases revolve around the abuse of immigrant women, because abusers know these victims have not one but two impediments to seeking legal help.
For a short time 5-10 years ago I thought we might be near a breakthrough in softening the penalties on women voluntarily seeking to make a living through sex work. Now, my optimism has dimmed. The success the Right has had in enlisting parts of the Left in rebranding all prostitution as slavery has polluted discourse on this issue and means a lot of women will still be left outside the law.
“Let’s be real,” Newsom said in his first State of the State address on Tuesday. “The current project, as planned, would cost too much and respectfully take too long. There’s been too little oversight and not enough transparency.”
Hurray! This is long overdue. I was writing about how dumb an idea this was back in 2008. I remember it because I was on Fox and Friends in the worst time slot ever to talk about it. Not only was the interview at like 4AM Arizona time, but the segment immediately before I discussed economics and public policy *yawn* they had 8 cute maltese puppies frolicking on stage.
Everyone, including I would bet California officials but probably excepting elements of the fawning media, knew the cost estimates were a joke. In 2010 when CA said $30-$40 billion I said it would take at least $75 billion and when CA belatedly adopted that number I doubled it to $150 billion and I think that is still low for what it would have cost. This was all at a time when you could fly Burbank to Oakland on Southwest for $90.
But because it seems to be a rule that no CA politician can remain sane for more than 5 minutes straight, here are the next lines of the story:
Newsom, though, said he wants to finish construction already underway on a segment of the high-speed train through the Central Valley. The project would connect a 119-mile stretch from Merced to Bakersfield.
“I know that some critics are going to say, ‘Well, that’s a train to nowhere.’ But I think that’s wrong and I think that’s offensive,” Newsom said. “It’s about economic transformation. It’s about unlocking the enormous potential of the Valley.”
This is absolutely absurd. If you started with a clean sheet and studied what the Central Valley really needed for "economic transformation," I am willing to bet a high-speed rail line from Merced to Bakersfield would not be in the top 100 items, maybe not the top 1000. Probably first on the list for the Central Valley economy would be to stop applying minimum wage rates based on San Francisco to poorer rural areas of California. If you wanted to limit yourself to infrastructure projects, the Central Valley would probably beg for water infrastructure projects, not a silly overpriced train.
I know I have not been blogging serious topics much of late. In part this is due to just being busy -- holidays, end of year accounting closeouts for the business, and some geeky projects (a few raspberry pi things I will share soon). In part this is due to the fact that whenever I engage with social media too long I become a worse person and back away again. In part this is because my daughter said I needed to lighten up on my blog for a while. And in part this is to my not wanting my obsessive fascination with the trainwreck that is Tesla to dominate my blogging (though there are a couple of updates coming).
As I close in on my 15th(!) year on this blog, this sort of ebb and flow happens from time to time. I will be back in force soon.
The last thing we need now is even more expansion of executive power. I remember when, gosh it was like only two or three years ago, you Republicans were (rightly) bemoaning Obama's executive actions as unconstitutional expansions of Presidential power. You argued, again rightly, that just because Congress did not pass the President's cherished agenda items, that did not give the President some sort of right to do an end-around Congress.
But now, I hear many Republicans making exactly the same arguments on the wall that Obama made during his Presidency, with the added distasteful element of a proposed declaration of emergency to allow the army to go build the wall.
I personally think the wall is stupid, will solve nothing, and will be a moral blight on this country -- its ugly to think of use having our very own Berlin Wall. But forget all that, for now I am not arguing against the wall, but against the proposed process.
I can pretty much guarantee you that if Trump uses this emergency declaration dodge (and maybe even if he doesn't now that Republicans have helped to normalize the idea), the next Democratic President is going to use the same dodge. I can just see President Warren declaring a state of emergency to have the army build windmills or worse. In fact, if Trump declares a state of emergency on a hot-button Republican issue, Democratics partisans are going to DEMAND that their President do the same, if for no reason other than tribal tit for tat.
Postscript: Now that I am handing out political advice to Republicans, what is the deal with your Ocasio-Cortez fixation? I hear many folks on both sides of the aisle who attribute some of Trump's electoral success to the media fixation on him that kept him in the news constantly. I am reminded of the old Pepsi challenge, where Pepsi showed people choosing their product over Coke. But the thing was, while Pepsi's sales increased, so did Coke's because the commercials kept Coke's name prominent in people's minds and established it as the product to which everyone else compares themselves. Do you really want to do the same thing with Ocasio-Cortez?
Readers of this blog know that I have always been skeptical of the value of net neutrality rules. I see the Internet just like any other vertical value chain with multiple players, which we might oversimplify as content providers who hand off to bandwidth providers to get in front of the customer. Nearly every industry has these vertical value chains with multiple players -- think Coke and Pepsi fighting for floor space and margins through Wal-Mart. What is amazing to me is how the large content streamers, particularly Google, Netflix and Facebook, have somehow convinced the public that the whole future of the Internet depends on the government hamstringing the bandwidth providers in their relationship with the content producers.
When Youtube wants to stream at 4K rather than 1080p, the majority of the instractructure hit is on the bandwidth provides, and Google/Youtube wants that bandwidth to be there but does not want to have to pay for any of it. That is why these companies are the main supporters of net neutrality, but they are smart enough not to say this, but to instead flog some mythology that bandwidth providers might block or discriminate against certain providers. Even supporters of this meme are forced to agree that it is wholly hypothetical, that no one can really point to any good examples of it happening (I have always suspected that general public hatred for Comcast in particular has created more support for net neutrality than anything else).
This argument for net neutrality is even odder as clear discrimination and deplatforming is happening on the Internet apparently everywhere BUT with the bandwidth providers. Or as I wrote on Twitter:
I might be unable to get a domain registered. I might not get hosted. I might not get anyone to handle my payments. I might not be able to syndicate on any social media. Google might not show me in searches. But by God Comcast is going to give equal treatment to my traffic!
This is my usual long-winded lead in for a very good article I read a while back and forgot to link. It's from Drew Clark at Cato and is titled "Seeking Intervention Backfired on Silicon Valley". I recommend the whole thing but here is a small piece:
The companies that drove the engine of America’s information technology machine essentially argued as follows: We provide the good stuff that you — the American consumer — want. You go to Google to get your searches answered. You want Facebook to keep up on posts from friends, families, and trusted content providers. Access to the content in the Apple iTunes store or to Amazon Prime streaming video subscriptions doesn’t need to be regulated because we tech giants compete vigorously among ourselves. But Washington does need to step in and regulate the telecom market because of a lack of competition among ISPs. And the FCC agreed in 2015 with what was officially dubbed the Open Internet Order. ...
Major content companies like Google, Facebook, and Netflix feared that ISPs would seek to throttle their services as a way of extracting payment for prioritization. Particularly for data-intensive video- streaming services like Netflix and Google’s YouTube, this concern had a certain economic logic, even as it remained hypothetical. Having long courted Silicon Valley as a key constituency and facing a highly visible public demand with enthusiastic grassroots support on the left, Obama complied....
Silicon Valley’s regulations-for-thee-but-not-for-me attitude has come back to bite them. They want the strictest form of regulation for telecommunications providers but no scrutiny of themselves, and now the tables have been turned.
Pai has not hesitated to point out the hypocrisy as he has moved to undo the net neutrality rules. In a November 29 speech in the lead-up to his net neutrality rollback, he said that the tech giants are “part of the problem” of viewpoint discrimination. “Indeed, despite all the talk about the fear that broadband providers could decide what internet content consumers can see, recent experience shows that so-called edge providers are in fact deciding what content they see. These providers routinely block or discriminate against content they don’t like.”
Today I want to come back to a topic I have not covered for a while, which is what I call knowledge or certainty "laundering" via computer models. I will explain this term more in a moment, but I use it to describe the use of computer models (by scientists and economists but with strong media/government/activist collusion) to magically convert an imperfect understanding of a complex process into apparently certain results and predictions to two-decimal place precision.
The initial impetus to revisit this topic was reading "Chameleons: The Misuse of Theoretical Models in Finance and Economics" by Paul Pfleiderer of Stanford University (which I found referenced in a paper by Anat R. Admati on dangers in the banking system). I will except this paper in a moment, and though he is talking more generically about theoretical models (whether embodied in code or not), I think a lot of his paper is relevant to this topic.
The labelling of the chart actually understates the heroic feat the authors achieved as their conclusion actually models wildfire with and without anthropogenic climate change. This means that first they had to model the counterfactual of what the climate could have been like without the 30ppm (0.003% of the atmosphere) CO2 added in the period. Then, they had to model the counterfactual of what the wildfire burn acreage would have been under the counter-factual climate vs. what actually occurred. All while teasing out the effects of climate change from other variables like forest management and fuel reduction policy (which --oddly enough -- despite substantial changes in this period apparently goes entirely unmentioned in the underlying study and does not seem to be a variable in their model). And they do all this for every year back to the mid-1980's.
Don't get me wrong -- this is a perfectly reasonable analysis to attempt, even if I believe they did it poorly and am skeptical you can get good results in any case (and even given the obvious fact that the conclusions are absolutely not testable in any way). But any critique I might have is a normal part of the scientific process. I critique, then if folks think it is valid they redo the analysis fixing the critique, and the findings might hold or be changed. The problem comes further down the food chain:
When the media, and in this case the US government, uses this analysis completely uncritically and without any error bars to pretend at certainty -- in this case that half of the recent wildfire damage is due to climate change -- that simply does not exist
And when anything that supports the general theory that man-made climate change is catastrophic immediately becomes -- without challenge or further analysis -- part of the "consensus" and therefore immune from criticism.
I like to compare climate models to economic models, because economics is the one other major field of study where I think the underlying system is as nearly complex as the climate. Readers know I accept that man is causing some warming via CO2 -- I am a lukewarmer who has proposed a carbon tax. However, as an engineer whose undergraduate work focused on the dynamics of complex systems, I go nuts with anti-scientific statements like "Co2 is the control knob for the Earth's climate." It is simply absurd to say that an entire complex system like climate is controlled by a single variable, particularly one that is 0.04% of the atmosphere. If a sugar farmer looking for a higher tariff told you that sugar production was the single control knob for the US climate, you would call BS on them in a second (sugar being just 0.015% by dollars of a tremendously complex economy).
But in fact, economists play at these same sorts of counterfactuals. I wrote about economic analysis of the effects of the stimulus way back in 2010. It is very similar to the wildfire analysis above in that it posits a counter-factual and then asserts the difference between the modeled counterfactual and reality is due to one variable.
Last week the Council of Economic Advisors (CEA) released its congressionally commissioned study on the effects of the 2009 stimulus. The panel concluded that the stimulus had created as many as 3.6 million jobs, an odd result given the economy as a whole actually lost something like 1.5 million jobs in the same period. To reach its conclusions, the panel ran a series of complex macroeconomic models to estimate economic growth assuming the stimulus had not been passed. Their results showed employment falling by over 5 million jobs in this hypothetical scenario, an eyebrow-raising result that is impossible to verify with actual observations.
Most of us are familiar with using computer models to predict the future, but this use of complex models to write history is relatively new. Researchers have begun to use computer models for this sort of retrospective analysis because they struggle to isolate the effect of a single variable (like stimulus spending) in their observational data. Unless we are willing to, say, give stimulus to South Dakota but not North Dakota, controlled experiments are difficult in the macro-economic realm.
But the efficacy of conducting experiments within computer models, rather than with real-world observation, is open to debate. After all, anyone can mine data and tweak coefficients to create a model that accurately depicts history. One is reminded of algorithms based on skirt lengths that correlated with stock market performance, or on Washington Redskins victories that predicted past presidential election results.
But the real test of such models is to accurately predict future events, and the same complex economic models that are being used to demonstrate the supposed potency of the stimulus program perform miserably on this critical test. We only have to remember that the Obama administration originally used these same models barely a year ago to predict that unemployment would remain under 8% with the stimulus, when in reality it peaked over 10%. As it turns out, the experts' hugely imperfect understanding of our complex economy is not improved merely by coding it into a computer model. Garbage in, garbage out.
Remember what I said earlier: The models produce the result that there will be a lot of anthropogenic global warming in the future because they are programmed to reach this result. In the media, the models are used as a sort of scientific money laundering scheme. In money laundering, cash from illegal origins (such as smuggling narcotics) is fed into a business that then repays the money back to the criminal as a salary or consulting fee or some other type of seemingly legitimate transaction. The money he gets
back is exactly the same money, but instead of just appearing out of nowhere, it now has a paper-trail and appears more legitimate. The money has been laundered.
In the same way, assumptions of dubious quality or certainty that presuppose AGW beyond the bounds of anything we have see historically are plugged into the models, and, shazam, the models say that there will be a lot of anthropogenic global warming. These dubious assumptions, which are pulled out of thin air, are laundered by being passed through these complex black boxes we call climate models and suddenly the results are somehow scientific proof of AGW. The quality hasn't changed, but the paper trail looks better, at least in the press. The assumptions begin as guesses of dubious quality and come out laundered at "settled science."
Back in 2011, I highlighted a climate study that virtually admitted to this laundering via model by saying:
These question cannot be answered using observations alone, as the available time series are too short and the data not accurate enough. We therefore used climate model output generated in the ESSENCE project, a collaboration of KNMI and Utrecht University that generated 17 simulations of the climate with the ECHAM5/MPI-OM model to sample the natural variability of the climate system. When compared to the available observations, the model describes the ocean temperature rise and variability well.”
I wrote in response:
[Note the first and last sentences of this paragraph] First, that there is not sufficiently extensive and accurate observational data to test a hypothesis. BUT, then we will create a model, and this model is validated against this same observational data. Then the model is used to draw all kinds of conclusions about the problem being studied.
This is the clearest, simplest example of certainty laundering I have ever seen. If there is not sufficient data to draw conclusions about how a system operates, then how can there be enough data to validate a computer model which, in code, just embodies a series of hypotheses about how a system operates?
A model is no different than a hypothesis embodied in code. If I have a hypothesis that the average width of neckties in this year’s Armani collection drives stock market prices, creating a computer program that predicts stock market prices falling as ties get thinner does nothing to increase my certainty of this hypothesis (though it may be enough to get me media attention). The model is merely a software implementation of my original hypothesis. In fact, the model likely has to embody even more unproven assumptions than my hypothesis, because in addition to assuming a causal relationship, it also has to be programmed with specific values for this correlation.
This brings me to the paper by Paul Pfleiderer of Stanford University. I don't want to overstate the congruence between his paper and my thoughts on this, but it is the first work I have seen to discuss this kind of certainty laundering (there may be a ton of literature on this but if so I am not familiar with it). His abstract begins:
In this essay I discuss how theoretical models in finance and economics are used in ways that make them “chameleons” and how chameleons devalue the intellectual currency and muddy policy debates. A model becomes a chameleon when it is built on assumptions with dubious connections to the real world but nevertheless has conclusions that are uncritically (or not critically enough) applied to understanding our economy.
The paper is long and nuanced but let me try to summarize his thinking:
In this essay I discuss how theoretical models in finance and economics are used in ways that make them “chameleons” and how chameleons devalue the intellectual currency and muddy policy debates. A model becomes a chameleon when it is built on assumptions with dubious connections to the real world but nevertheless has conclusions that are uncritically (or not critically enough) applied to understanding our economy....
My reason for introducing the notion of theoretical cherry picking is to emphasize that since a given result can almost always be supported by a theoretical model, the existence of a theoretical model that leads to a given result in and of itself tells us nothing definitive about the real world. Though this is obvious when stated baldly like this, in practice various claims are often given credence — certainly more than they deserve — simply because there are theoretical models in the literature that “back up” these claims. In other words, the results of theoretical models are given an ontological status they do not deserve. In my view this occurs because models and specifically their assumptions are not always subjected to the critical evaluation necessary to see whether and how they apply to the real world...
As discussed above one can develop theoretical models supporting all kinds of results, but many of these models will be based on dubious assumptions. This means that when we take a bookshelf model off of the bookshelf and consider applying it to the real world, we need to pass it through a filter, asking straightforward questions about the reasonableness of the assumptions and whether the model ignores or fails to capture forces that we know or have good reason to believe are important.
I know we see a lot of this in climate:
A chameleon model asserts that it has implications for policy, but when challenged about the reasonableness of its assumptions and its connection with the real world, it changes its color and retreats to being a simply a theoretical (bookshelf) model that has diplomatic immunity when it comes to questioning its assumptions....
Chameleons arise and are often nurtured by the following dynamic. First a bookshelf model is constructed that involves terms and elements that seem to have some relation to the real world and assumptions that are not so unrealistic that they would be dismissed out of hand. The intention of the author, let’s call him or her “Q,” in developing the model may be to say something about the real world or the goal may simply be to explore the implications of making a certain set of assumptions. Once Q’s model and results become known, references are made to it, with statements such as “Q shows that X.” This should be taken as short-hand way of saying “Q shows that under a certain set of assumptions it follows (deductively) that X,” but some people start taking X as a plausible statement about the real world. If someone skeptical about X challenges the assumptions made by Q, some will say that a model shouldn’t be judged by the realism of its assumptions, since all models have assumptions that are unrealistic. Another rejoinder made by those supporting X as something plausibly applying to the real world might be that the truth or falsity of X is an empirical matter and until the appropriate empirical tests or analyses have been conducted and have rejected X, X must be taken seriously. In other words, X is innocent until proven guilty. Now these statements may not be made in quite the stark manner that I have made them here, but the underlying notion still prevails that because there is a model for X, because questioning the assumptions behind X is not appropriate, and because the testable implications of the model supporting X have not been empirically rejected, we must take X seriously. Q’s model (with X as a result) becomes a chameleon that avoids the real world filters.
Check it out if you are interested. I seldom trust a computer model I did not build and I NEVER trust a model I did build (because I know the flaws and assumptions and plug variables all too well).
By the way, the mention of plug variables reminds me of one of the most interesting studies I have seen on climate modeling, by Kiel in 2007. It was so damning that I haven't seen anyone do it since (at least get published doing it). I wrote about it in 2011 at Forbes:
My skepticism was increased when several skeptics pointed out a problem that should have been obvious. The ten or twelve IPCC climate models all had very different climate sensitivities -- how, if they have different climate sensitivities, do they all nearly exactly model past temperatures? If each embodies a correct model of the climate, and each has a different climate sensitivity, only one (at most) should replicate observed data. But they all do. It is like someone saying she has ten clocks all showing a different time but asserting that all are correct (or worse, as the IPCC does, claiming that the average must be the right time).
The answer to this paradox came in a 2007 study by climate modeler Jeffrey Kiehl. To understand his findings, we need to understand a bit of background on aerosols. Aerosols are man-made pollutants, mainly combustion products, that are thought to have the effect of cooling the Earth's climate.
What Kiehl demonstrated was that these aerosols are likely the answer to my old question about how models with high sensitivities are able to accurately model historic temperatures. When simulating history, scientists add aerosols to their high-sensitivity models in sufficient quantities to cool them to match historic temperatures. Then, since such aerosols are much easier to eliminate as combustion products than is CO2, they assume these aerosols go away in the future, allowing their models to produce enormous amounts of future warming.
Specifically, when he looked at the climate models used by the IPCC, Kiehl found they all used very different assumptions for aerosol cooling and, most significantly, he found that each of these varying assumptions were exactly what was required to combine with that model's unique sensitivity assumptions to reproduce historical temperatures. In my terminology, aerosol cooling was the plug variable.
When I was active doing computer models for markets and economics, we used the term "plug variable." Now, I think "goal-seeking" is the hip word, but it is all the same phenomenon.
Postscript, An example with the partisans reversed: It strikes me that in our tribalized political culture my having criticised models by a) climate alarmists and b) the Obama Administration might cause the point to be lost on the more defensive members of the Left side of the political spectrum. So let's discuss a hypothetical with the parties reversed. Let's say that a group of economists working for the Trump Administration came out and said that half of the 4% economic growth we were experiencing (or whatever the exact number was) was due to actions taken by the Trump Administration and the Republican Congress. I can assure you they would have a sophisticated computer model that would spit out this result -- there would be a counterfactual model of "with Hillary" that had 2% growth compared to the actual 4% actual under Trump.
Would you believe this? After all, its science. There is a model. Made by experts ("top men" as they say in Raiders of the Lost Ark). Do would you buy it? NO! I sure would not. No way. For the same reasons that we shouldn't uncritically buy into any of the other model results discussed -- they are building counterfactuals of a complex process we do not fully understand and which cannot be tested or verified in any way. Just because someone has embodied their imperfect understanding, or worse their pre-existing pet answer, into code does not make it science. But I guarantee you have nodded your head or even quoted the results from models that likely were not a bit better than the imaginary Trump model above.
I have resisted Instagram for years because a) they only really allow photo uploads from your phone (not your pc) and b) none of my good photos are on my phone. It is just really difficult to take a photography platform seriously that only really supports the crappiest end of the camera spectrum (i.e. phones).
However, a couple of things have changed. One, Instagram is now a powerful social media platform and useful to my business given that I am trying to get young people to go to outdoors locations that are photogenic. And two, I have gotten comfortable with a couple of hacks to be able to use instagram from my pc (more in a second).
So if you are into Instagram, you can follow me now. My business instagram for our campgrounds and parks is @camprrm. My personal instagram mainly to be filled with travel photography is @coyoteblog. Actually the other reason I have come around on Instagram is that I wanted to follow my daughter Amelia who is a student artist, and instagram is THE way to advertise one's portfolio. She is at @meliameyer (see what she did there, millenials are much more clever with integrating symbols into an extended alphabet).
The two hacks I use are: 1) Convert the instagram account to a business account and then use the free version of hootsuite to post to it. Even works with scheduled posts. This works well for one account but is hard to make work for two. 2) Open and log into instagram via chrome. Right click on the white space of the web page somewhere and choose inspect. I think there is also a keyboard shortcut to do this, maybe cntl-shift-i. Once the inspect window pops up, click on the little icon in the upper left that looks like a cell phone. Poof, your browser is in cell phone sim mode and instagram should suddenly give you the + button (refresh page if it doesn't) that will allow you to post pictures right from your computer hard drive.
I will let him explain the chart, it is worth understanding:
The authors collected every significant clinical study of drugs and dietary supplements for the treatment or prevention of cardiovascular disease between 1974 and 2012. Then they displayed them on a scatterplot.
Prior to 2000, researchers could do just about anything they wanted. All they had to do was run the study, collect the data, and then look to see if they could pull something positive out of it. And they did! Out of 22 studies, 13 showed significant benefits. That’s 59 percent of all studies. Pretty good!
Then, in 2000, the rules changed. Researchers were required before the study started to say what they were looking for. They couldn’t just mine the data afterward looking for anything that happened to be positive. They had to report the results they said they were going to report.
And guess what? Out of 21 studies, only two showed significant benefits. That’s 10 percent of all studies. Ugh. And one of the studies even demonstrated harm, something that had never happened before 2000
Reports for all-cause mortality were similar. Before 2000, 5 out of 24 trials showed reductions in mortality. After 2000, not a single study showed a reduction in mortality.
Note that these sensible rules for conducting a study do NOT exist for pretty much any study in any field that you see in the media. Peer review generally does not address it. Links to the full study in Drum's article.
Tags: kevin drum, media Category: Science |
Comments Off on Incredible Evidence of P Hacking in Research Studies, Demonstrated with One Chart
Ten days ago, I told my wife that if Brett Kavanaugh is confirmed, he can probably thank Michael Avenatti and his client. Julie Swetnick's accusations of mass gang rapes held week after week after week were so batsh*t crazy -- and completely unconfirmed by any witnesses when the behavior she described was so public and affected so many people that confirmation should have been easy -- that the Democrats' argument that women never lie and always should be believed was shown to be false to all reasonable observers. It became too easy for Republicans to convince themselves that all of the women accusing Kavanaugh, not just Swetnick and the other last-minute copycats, were a put-up job by Democrats (a conclusion that was more easy to reach given DiFi's hamfisted attempt to be "tricky" and withhold the Ford accusations to the last minute). In a well-reasoned world, the veracity of the Swetnick accusations should have had no bearing on the evaluation of Ford's believably, but in the real world of politics it had a huge effect.
I honestly believe that an earlier reveal of the Ford accusations early in the process, without all the nutty copycat allegations, could easily have resulted in Kavanaugh being withdrawn. First, it would have allowed Republicans and Kavanaugh himself to escape early in the process before so many chips were on the table. Further, if we take Collins's speech at face value, her yes vote really resulted from the Swetnick accusations and I think she might easily have voted the other way with a different process.
Democrats, the left, and various other anti-Kavanaugh persons can thank attorney Michael Avenatti for this outcome, at least in part.
The spotlight-stealing lawyer, who also represented Stormy Daniels, is responsible for drawing the media's attention to Julie Swetnick, an alleged victim of Kavanaugh who told an inconsistent and unpersuasive story. Swetnick's wild accusation provided cover for fence-sitting senators to overlook the more plausible allegation leveled by psychology professor Christine Blasey Ford, and to declare that Kavanaugh was being subjected to false smears.
Update: Michael Avenatti has responded to such criticism on Twitter by saying, essentially, "what was I supposed to do, just ignore the needs of my client?" No. What he should have done is honestly thought about the needs of his client rather than just his need for self-promotion ahead of the Democratic primaries. It is very much a part of a lawyer's job to confirm his client's story and evaluate whether he thinks they have a good case, and then to counsel them on whether or not it makes sense for them given the cost in dollars and public harassment to try to bring the case. I have had a batsh*t crazy woman who was an ex-employee (who I have never met face to face) decide that I was doing all sorts of crazy things like running an Al Quaeda training camp, organizing a narcotics ring, and stalking her across every Indian casino in the state. The poor woman has mental health issues and imagines all kinds of weird stuff, and I can be sympathetic now that she is no longer actively threatening me and I don't have to maintain protective orders against her. At the time she took her crazed stories to any number of lawyers trying to mount a case against me on all kinds of odd bases, and you know what - no lawyer took the case, because pursuing this sort of madness in the legal system would not have done anyone, especially this woman, any good at all.
Most journalists become journalism majors because they had vowed after high school never, ever to take a math or science class again. At Princeton we had distribution requirements and you should have seen the squealing from English and History majors at having to take one science course (I don't remember ever hearing the reverse from engineering majors).
It should not surprise you, then, that most media is awful at science journalism. I held off making a comment on this for 3 days figuring it was a typo and they would quickly fix it, but apparently not. This fits in well with my thesis that the art of sanity-checking numbers has been lost (I added the bold):
The space elevator is the Holy Grail of space exploration,” says Michio Kaku, a professor of physics at City College of New York and a noted futurist. “Imagine pushing the ‘up’ button of an elevator and taking a ride into the heavens. It could open up space to the average person.”
Kaku isn’t exaggerating. A space elevator would be the single largest engineering project ever undertaken and could cost close to $10 billion to build. But it could reduce the cost of putting things into orbit from roughly $3,500 per pound today to as little as $25 per pound, says Peter Swan, president of International Space Elevator Consortium (ISEC), based in Santa Ana, California.
LOL. The planning for such a structure would cost more than $10 billion. There is no way that a space elevator can be built for just 1/10 the price of a high speed rail line from LA to San Francisco. Even at $10 trillion dollars, or 3 orders of magnitude more, I would nod my head and think that was a pretty inexpensive price.
I never meet with young women one-on-one any more. If I am interviewing a young woman for college, we meet in the Starbucks rather than my office. I try to meet with sales people via the web rather than face-to-face, but if a young female sales person does show up at my door and I really must meet with them, we do it downstairs in the lobby and not in my office.
I do not know if Kavanaugh is guilty or innocent at this point of a range of alleged actions that range from boorish behavior to attempted sexual assault. Like most folks I await their testimony tomorrow, but perhaps unlike most folks I have a lot of experience trying to adjudicate he-said-she-said conflicts (in the workplace and with customers) and I am reconciled to the fact that we may never be certain of the truth.
What I do know is that having many prominent people in the media and in the highest levels of government claim that a woman's accusation, without any other due process, is enough to convict a man and destroy his career and reputation just proves to me that my policy is absolutely justified. Because even if Kavanaugh's accusers are absolutely correct and honest, the next one's may not be, especially if we establish a rewards system for public accusations of this sort.
My wife tells me I am being incredibly unfair -- how can young women ever advance and get mentored if every male business executive (and males still dominate the c-suite) takes this attitude? Well, let me give an analogy. Let's assume that in reaction to years of abuse, young female actresses made a pact or formed a union. In doing so they agree to never meet with a male director or producer alone. Many directors and producers could reasonably complain that they weren't threats, and this action unfairly punishes them by making their jobs harder. The women would reasonably retort, "perhaps, but as long as the rules are such that if we get assaulted in that room then we have absolutely no recourse for justice -- under these rules we aren't going in to the room. Sure, it may only be a small percentage are predators, but we can't know who is who until after the damage is done."
Would anyone think this was unfair? Perhaps they might be accused of overreacting -- and I am willing to accept that maybe I am over-reacting as well. But I worked 3 years in a refinery, wearing a hard hat and eye protection every minute of that time, and I don't remember anything ever hitting my head or my glasses. But that does not make these things irrational precautions.
Tags: college, media Category: Gender |
Comments Off on The One Thing I am Sure About In the Whole Kavanaugh Brouhaha -- That My Policy of Not Meeting With Young Women Alone Is Absolutely Justified
Most of you know I agree there is man-made global warming but am skeptical the extent will be anywhere near most forecasts you see in the media. For some reason, this earns me the title of "denier." However, I find that the climate discussion has become boring in the extreme, and I have mostly moved on from it. But I am still interested in analytical abuses in the media, and long-time readers will know that my favorite is the positing of a trend using but a single data point. My example today happens to be from climate.
It starts with this tweet:
As extreme weather events become more common, we're living through "once in lifetime storms" every year. Our most immediate understanding of their severity is loss of life and damages.
Obviously he is reacting to the recent hurricane in North Carolina, which turns out to be pretty run of the mill but the media has portrayed as some sort of armageddon. I could have pulled roughly similar quotes from all kinds of sources. Several networks did long pieces over the weekend claiming an upward trend in hurricanes without any trend data, but merely from the fact that one made landfall recently. But anyone who claims be defending science should be held, I think, to a higher standard in making scientific claims.
As I asked the March for Science tweeter: If, say, there is a trend towards more or stronger hurricanes, why does no one ever show a trend chart? They just declare the trend from one data point, like a single hurricane landfall. Every long-term hurricane & cyclonic energy trend chart I have seen is flat to down. (This is not primarily a climate post but I will post some hurricane trend charts at the end).
There is certainly an upwards trend in the media labelling storms as "once in a lifetime" but it is doubtful that there is actually an underlying trend in storm severity. Even the slightly more meaningful term "100-year _____" is abused.
Consider a 100-year flood in North Carolina, almost certainly a once in a lifetime event for someone in that state unless they live really long. Since North Carolina is .027% of the world's landmass, there will be, on average, 37 hundred-year floods over land areas the size of North Carolina every single year. That's 37 once-in-a-lifetime North-Carolina-sized floods somewhere in the world every single year. Heck, there should be 3-4 thousand-year floods of North Carolina size somewhere in the world every year -- that's three or four once in a millenium floods! And this same math applies to 100-year heat waves, droughts, snow storms -- you name it.
We can learn a couple of things from this. First, living through "once in a lifetime" storms every year, somewhere in the world, is not abnormal -- it is expected. Second, one can see how choices in media coverage could drive an apparent trend. If the media covered maybe 3 or 4 of these 37 floods when I was young, but covers every one today, it will appear that there is a trend since I hear so much more about them. But in fact, nothing will have changed except the media. I will remind you what I wrote on this topic waaaay back in 2012.
Let's take a step back to 2001 and the "Summer of the Shark." The media hysteria began in early July, when a young boy was bitten by a shark on a beach in Florida. Subsequent attacks received breathless media coverage, up to and including near-nightly footage from TV helicopters of swimming sharks. Until the 9/11 attacks, sharks were the third biggest story of the year as measured by the time dedicated to it on the three major broadcast networks' news shows.
Through this coverage, Americans were left with a strong impression that something unusual was happening -- that an unprecedented number of shark attacks were occurring in that year, and the media dedicated endless coverage to speculation by various "experts" as to the cause of this sharp increase in attacks.
Except there was one problem -- there was no sharp increase in attacks. In the year 2001, five people died in 76 shark attacks. However, just a year earlier, 12 people had died in 85 attacks. The data showed that 2001 actually was a down year for shark attacks.
Once you start looking for this type of thing, the extrapolation of a trend from at most one data point, you will see it everywhere.
For those still hanging around to the end, here are a couple of actual trend charts on hurricanes (the adjusted line attempts to correct for the fact that earlier eras with no satellites or radar tended to miss some hurricanes) (source at NOAA):
Below are two charts that look beyond just the Atlantic at global cyclones, both from this source. The first is frequency:
The second looks at accumulated cyclonic energy, which is a sort of time integral of the energy in all active cyclonic storms around the world
Later in the tweetstorm, the same tweeter mentioned as a fact, again without data, "Climate change is increasing drought frequency, impacting everything from agriculture to health. Some studies suggest the consequences of droughts include increased violence and war." There has been no upward trend in US droughts (negative is more drought-y.
Finally, in the spirit of full disclosure, of all the zillions of things (not directly related to temperature) in weather effects that are blamed on global warming, this is the only one I have found that shows an upward trend recently and could logically be attributed to warming. Whether this is related to warming or independent or a data measurement issue is (if folks were honest) not well understood
Naomi Osaka, 20 years old, just became the first player from Japan to win a Grand Slam.
Yet rather than cheer Osaka, the crowd, the commentators and US Open officials all expressed shock and grief that Serena Williams lost.
Osaka spent what should have been her victory lap in tears. It had been her childhood dream to make it to the US Open and possibly play against Williams, her idol, in the final.
It’s hard to recall a more unsportsmanlike event.
Here was a young girl who pulled off one of the greatest upsets ever, who fought for every point she earned, ashamed.
At the awards ceremony, Osaka covered her face with her black visor and cried. The crowd booed her. Katrina Adams, chairman and president of the USTA, opened the awards ceremony by denigrating the winner and lionizing Williams — whose ego, if anything, needs piercing.
“Perhaps it’s not the finish we were looking for today,” Adams said, “but Serena, you are a champion of all champions.” Addressing the crowd, Adams added, “This mama is a role model and respected by all.”
Incredibly, much of the media and powerful celebrities have rallied around Ms. Williams to claim that she is actually the victim. She claims she was a victim of sexism in the match, but she was playing (and getting beat) by another woman. She claims she was a victim of racism in the match because she is a woman of color, but she was not playing a white woman. She claims to be a victim of the tennis establishment when in fact she is the most powerful person in women's tennis (maybe ever) and wields far more wealth and power than anyone on that court that day -- a power and privilege demonstrated by the fact that all the other powerful and privileged rallied to her side immediately after the match.
For a while I have been thinking about a jumble of interrelated issues: problems with civil discourse, particularly the tribalization of politics and social media; a personal aspiration to be better at Caplan's ideological Turing test on a number of issues; and a skepticism that pleas for civility are really going to achieve more than just becoming another form of virtue signalling.
So what I have decided to start a new series with a number of policy proposals that are as broad in their appeal as I can make them. And in saying this I am not just going to present libertarian plans and call them non-partisan -- I bring libertarian-ish leanings to these proposals, but I will also diverge from the hard core libertarian position on each. I use trans-pipartisan" as a shortcut term to say they are meant to simultaneously play on all of Arnold Kling's three axes of politics.
As a warning, I am not a policy expert and a large reason I present these is to develop and clarify my own thinking. Some will be well-developed -- the climate plan is in its 3rd or 4th iteration -- and some like the education plan is just a jumble of thoughts in my brain right now.
This article in something called Inside Climate News seems to be typical of many I have seen this year: Because we have had much attention in the media on heat waves this year, there must be an upward trend in heat waves and that is a warning signal that man-made global warming is destroying the planet. Typical of these articles are a couple of features
Declaration of a trend without any actual trend data, but just a single data point of events this year
Unstated implication that there must be a trend because the author can't remember another year when heat wave stories were so prevalent in the media
Unproven link to man-made global warming, because I guess both involve warmth.
I have no idea if well-publicized heat waves this year are a harbinger of an accelerating global warming trend. But since we are discussing "trends" it struck me as useful to actually liven up the discussion with some actual trend data, ie data for more than one summer. There is a real danger to extrapolating trends from volume of media coverage, as I discussed here. If you don't want to click through, I have a funny story in the postscript.
First, our most reliable temperature trend data does not really show a spike in temperatures this summer. Remember, a heat wave that covered the entire US would only affect 6% of the world's landmass and <2% of the world's total area (source). You can easily see the trend upwards several tenths of a degree over the last 40 years, but it is impossible to see much unique about the last 3 months of summer.
Second, there really is no substantial upward trend in US heat wave index (from right off the EPA's web site, as are all of the following charts. Look at the source for yourself to make sure I am not playing games). Note that all of the following charts are through 2016 and do NOT include the recent summer but are pretty meaningful none-the-less.
Third, in most of the country, there is actually a downward trend rather than upward trend in extreme heat days.
Pretty much everyone agrees, skeptics included, that the world and the US has warmed. So why are extreme heat days down in many locations, and certain down from the 1930's? This defies our intuition. The explanation is in part due to a feature of global warming that is seldom explained well by the media, that much of the warming we see and as predicted in climate models is in the night. We are seeing some increase in hot daytime highs, but really not at an unprecedented level over the last century. BUT, we see MUCH more of a trend in hot daily lows, which basically means warming evenings.
I spoke at Amherst College a while back and here was their temperature trends, broken up between daily highs and nighttime lows. All of Amherst's temperature trend since 1950 has not been in increased daytime highs but higher nighttime lows. This is a pattern you see repeated over and over at nearly every temperature station.
This is why I consider media reports of heat waves, at least of the scope we have seen to date, absolutely irrelevant to "proving" the world is warming.
let's take a step back to 2001 and the "Summer of the Shark." The media hysteria began in early July, when a young boy was bitten by a shark on a beach in Florida. Subsequent attacks received breathless media coverage, up to and including near-nightly footage from TV helicopters of swimming sharks. Until the 9/11 attacks, sharks were the third biggest story of the year as measured by the time dedicated to it on the three major broadcast networks' news shows.
Through this coverage, Americans were left with a strong impression that something unusual was happening -- that an unprecedented number of shark attacks were occurring in that year, and the media dedicated endless coverage to speculation by various "experts" as to the cause of this sharp increase in attacks.
Except there was one problem -- there was no sharp increase in attacks. In the year 2001, five people died in 76 shark attacks. However, just a year earlier, 12 people had died in 85 attacks. The data showed that 2001 actually was a down year for shark attacks.
Update: I am not really an active participant in the climate scene any more, particularly when positions hardened and it was impossible to really have an interesting discussion any more. The implicit plea in this post goes beyond climate -- if you are claiming a trend, show me the trend data. I can be convinced. There is clear trend data that temperatures are increasing so I believe there is an upward trend in temperatures. Show me the same for droughts or heat waves or hurricanes and I will believe the trend about those as well, but so often the actual data never matches the arm-waving in these media sources.
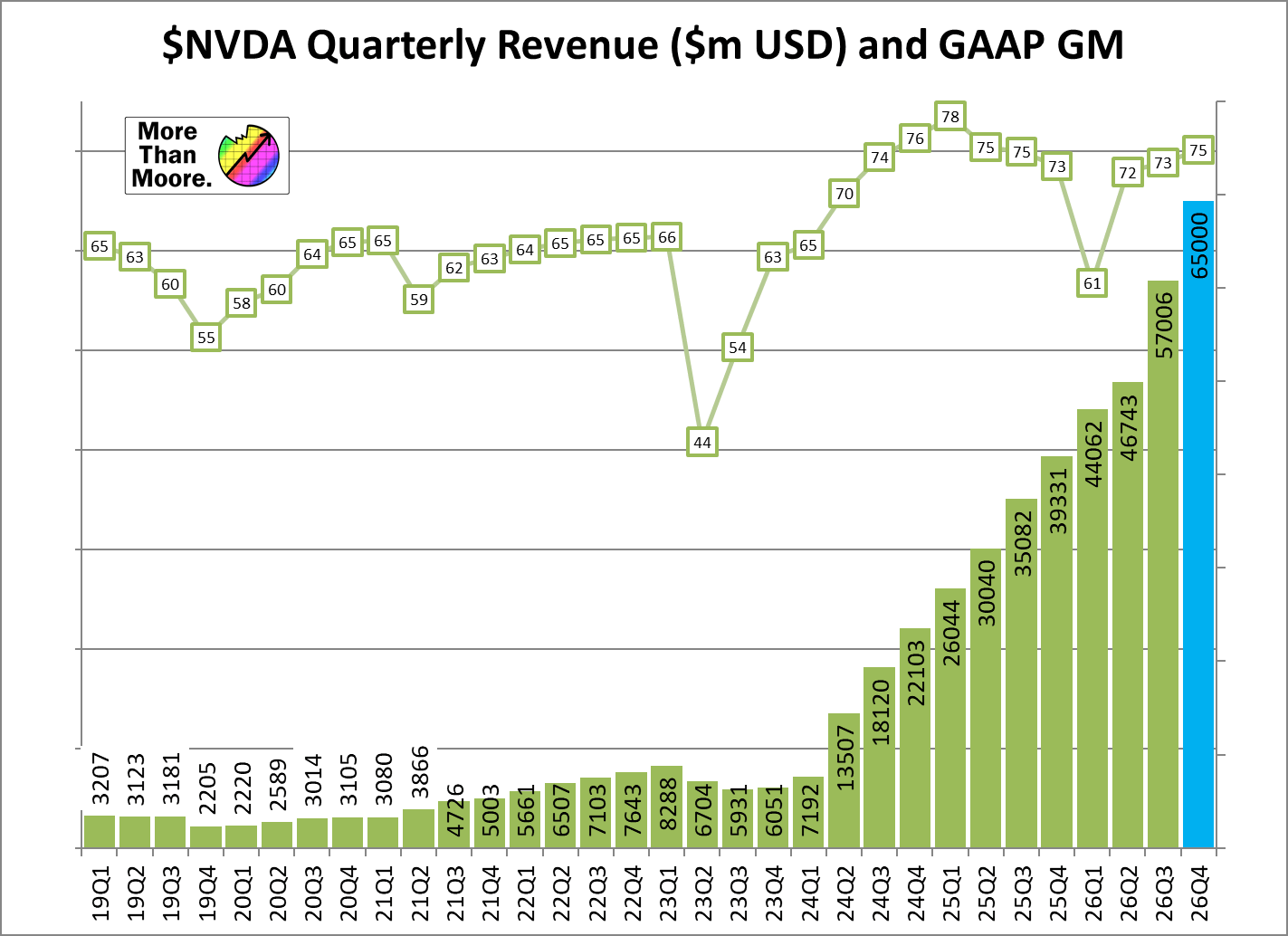
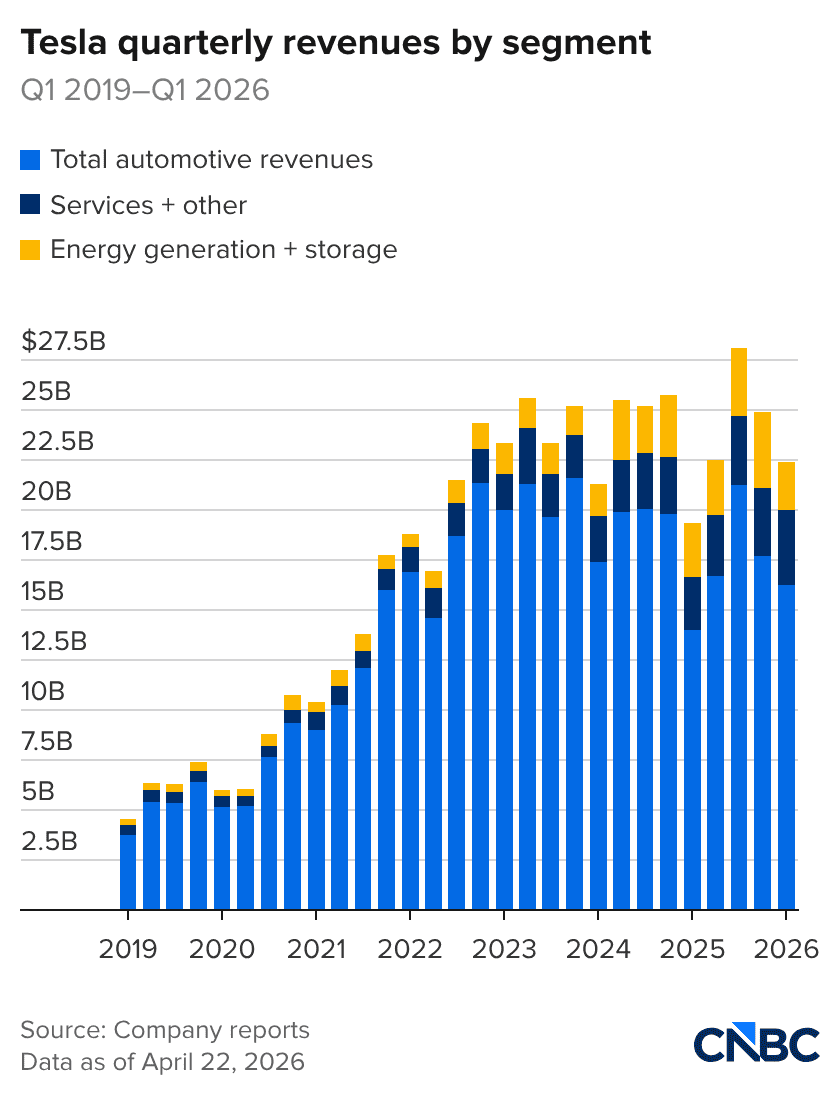














{kind=link}